In this article we look at consistency vs availability in an event-sourced system and the importance of well designed data modeling for improved data quality, reduce risks and increase performance.
Just like Relational Databases, data modeling is important for Event Sourced systems. A well designed data model will:- Improve data quality (duplication, consistency, outdated-ness, accuracy, etc.)
- Simplify complex and long running business processes
- Reduce risks from rapid business changes
- Reduce code complexity of complicated business domains
- Ensure devs can work well together within a team and with other teams
- Improve integration with external systems
- Improve understanding and collaboration between business units
- Increase performance, availability, and scalability
- And a whole lot more!!
How Systems Are Updated
Most systems need to make updates to a database, whether to transfer funds between bank accounts or buy something online.
Depending on how your data model is designed, it is updated in a consistent or available manner. In the Event Sourcing community this is more commonly known as transactional or .
Have you ever wondered why some systems fall apart when they experience high load? Or how to coordinate large numbers of people and systems to perform the same task together?
Designing a proper data model early is vital, as it is often the hardest thing to change during the lifetime of a system. A database can be tuned and code can be patched. But how your team, business users, and customers perceive the system is hard, time-consuming, and expensive to change.
Consistency vs Availability
Have you ever dreamt of developing a system where everything in the world can be changed at once without fail? What will you do with it?
Thankfully Computer Scientist, Eric Brewer, proved that such a system cannot exist with his famous CAP theorem:
A distributed system cannot simultaneously be consistent, available, and partition tolerant where:
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
According to the theorem, these 3 guarantees can not all exist at once for any distributed system: consistency, availability, partition tolerance. Let's break it down into something more digestible:
- Consistency: The system updates either every component or nothing at all. Even if it's slow or fails.
- Availability: The system updates quickly and rarely fails. Even if it's not consistent across components.
- Partition tolerance: The system updates many components and has to handle partitions* between them.
With this, we can dumb down the theorem to:
Given a distributed system has to update many components, it can't simultaneously change everything at once, quickly, without failure.
This can be further broken down into each of the 3 guarantees like this for another point of view:
Given a distributed system has to update many component (partition tolerance), it can't simultaneouslyChange everything at once (consistency), and do so
Quickly, without failure (availability)
Imagine we have a distributed system with many replicated databases across different networks. Say only one database was replicated during an update before it incurred a network failure.
In this case, the update can be designed to either:
- Fail, or
- Continue
With design #1, the system gives up availability (since the update fails), but still guarantees consistency (everything changes at once or nothing at all).
With design #2, the system gives up consistency (since only few components are updated, and not everything at once), but guarantees availability (it did not fail).
And since it can only be designed one way or the other: Any partition tolerant system can only have consistency or availability. Not both.
NOTE: This is a simplification of the proof so if you want more detail, you can read an illustrated version of this, or the actual paper.
A System Can Only Make 3 Guarantees Between Consistency & Availability
Because of this, a system can make these 3 types of guarantees:
- Available-Partition (AP)
- Consistent-Partition (CP)
- Consistent-Available (CA)
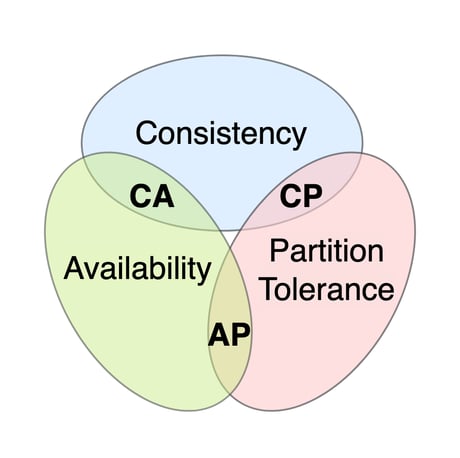
| Consistent | Available | Partition Tolerant | Also known as |
|---|---|---|---|
| ❌ | ✅ | ✅ | Available-Partition (AP) |
| ✅ | ❌ | ✅ | Consistent-Partition (CP) |
| ✅ | ✅ | ❌ | Consistent-Available (CA) |
Let's take a closer look at each of these:
Available-Partition (AP)
- Given a system has to update to many components (partition tolerance) it can be done
- Quickly and without failure (availability)
- But not to everything at once (no consistency)
Characteristics
- Usually fast and resilient, rarely fails
- Components are usually loosely coupled
- Data may be inconsistent across components
- May involve complex coordination such as compensating actions for synchronization
Typical Involves
- Asynchronous Call
- One-Way-Messages
- Fire-and-Forget
- Publish/Subscribe
- Process Manager/Saga
- Optimistic Locking
Consistent-Partition (CP)
- Given a system has to update to many components (partition tolerance) it can change
- Everything at once (consistency), but may do so
- Slowly or even fail all together (no availability)
Characteristics
- Data is typically consistent across components
- Logic is straightforward, generally simple and convenient to understand
- Can be slow and brittle, prone to failure
- Components can become tightly coupled
Typically Involves
- Synchronous calls
- Remote Procedural Calls
- Request/Response
- Database Transactions (e.g. Two-phase commit)
- Pessimistic Locking
Consistent-Available (CA)
- Given a system has to update only one component (no partition), it can change
- Everything at once (consistency), and
- Quickly, without failure (availability)
Characteristics
- Data is usually both consistent and available
- Usually simplistic systems that are less scalable
What the CAP Theorem tells us
1. Extra Partition Complicates Things
In systems where there is only one component, there will be no partition and communication issue. In this case both consistency and available can happen together in an update, say, via a database transaction. And since there's no other component to update, the operation is usually fast. These are typically simple operations, like saving an excel spreadsheet sitting on a local disk of a single laptop that is not shared to anyone. This is a CA operation, and due to its simplicity and reliability, we should always strive for it when there's no partition.
However, in a system where there are thousands of components, a large number of partitions can happen and the chance of a communication issue becomes exponentially higher. In this case, the CAP theorem tells us such system must be either consistent (i.e. CP - may be slow and can fail often), or available (AP - data may appear inconsistent) and can't be both.
2. How to Choose between CP, AP, and CA
Choosing between CP, AP, and CA really depends on the original intention of the update.
In General, if an update is protecting some important business rule/invariant and having data inconsistency is costly, then choose CP.
If an update requires speed and resiliency, then choose AP.
But if both of these are required, then consider reducing the number of components/partitions until both consistency and availability can be achieved.
3. Systems are Rarely only CP or AP
Developers often like to label certain systems and databases as either CP, and or AP. This is a gross simplification because many systems often behave CP for a set of operations and AP for others.
The determination of CP or AP does not happen on the system level. It happens on the operation level and arguably on the data model and the field level.
On the other hand, most systems may also have configurations that allow users to select how CP/AP their operation should be.
A system is neither CP nor AP. It is not black and white but is gray, with infinite levels of shading.
Examples of Consistency vs Availability Tradeoffs
1. Database Replication
Imagine we have a system where data is replicated across dozens nodes across multiple countries. This is typical in highly available systems. The system designer may have to choose whether an operation has to be committed to all, majority or even say just a single node. The former will lead to a consistent (CP) operation but the latter will be more available (AP).
Designing for consistency (CP) ensures everyone will see the same data at all times. But the operation becomes prone to failure since it has to save to dozens of nodes at the same time and one single network failure will sabotage the operation. The operation time will also be longer since it has to save to more nodes and coordinate more.
If we design for availability (AP) on the other hand, the operation will only have to save to one single node. This will be super fast to complete, will unlikely fail, and also vastly increases the throughput to allow more concurrent operations. However, the data will not be consistent for a long time while it replicates across the other dozens of nodes. Different users across geographies will see different data and this might be a source of confusion.
Whether we design for consistency or availability depends on many factors and a lot of times boils down to the actual use case as you'll see in the next example.
2. Apple Store Update
For another example, say Apple Inc., with hundreds of localized Apple store websites, is releasing its new iPhone on Black Friday. The company has paid many millions in advertising and it should absolutely not be released before that time.
The Apple store system designer can choose to publish it at the same instant across all Apple store websites globally under one single operation - this will be an example of an consistent operation.
On the other hand, say it has to increase the price of a 3rd party phone case by 50 cents globally. Since there's no sense of urgency, the price change can be published one site at a time until it is updated globally eventually. This operation is designed for availability.
Data Modeling and the CAP Theorem
The CAP Theorem is popularly used to discuss how databases behave with multiple distributed nodes and replication. However, it should also be used to understand how data model design can affect the consistency and availability of distributed system.
A data model that owns multiple entities will likely have operations that behave consistently on its own. Data models that are small and loosely coupled will likely find operations that requires availability characteristics across them.
For example, a bank will probably design data models involved in the withdrawal operations to be available in order to serve its millions of account holders. This may cause the account balances to be inconsistent between ATMs, branch systems, online banking etc., but it's a small price to pay compared to customer attrition from slow services.
In this case data models such as account, transaction, transfer and transfer limits are likely loosely coupled and are definitely not committed together in a single database transaction. Otherwise, throughput will suffer and the system may not be able to handle huge numbers of requests in short bursts.
However, the account data model is likely updated consistently on its own since its fields are likely updated at once via, say, a web form.
Event Sourcing and the CAP Theorem
The concept of a Relational Database was created back when the internet did not exist. It's mostly designed for consistent business operations that do not lend themselves very well to highly complex and scalable systems.
In contrast, databases using a state-transition model, such as EventStoreDB are designed and used for both consistent and available business operations and process with features such as streams, events, sequenced log, as well as subscriptions. This allows it to tackle all types of scenarios making it suitable to be the operational database in the new distributed world.
Conclusion
In this post we have discussed about:
- The importance of data modeling and its relationship with data consistency vs availability
- The CAP Theorem, what it means and the different characteristics and examples of consistent vs available systems
In the future post, we will discuss the foundation of data model design in order to satisfy consistent and available business operations, including consistency boundary, transactional vs eventual consistency, aggregate, and process managers.