In this article we explore the benefits of implementing Event Sourcing to your software architecture and the insights it can unlock for your business by providing richer data.
If you’re new to Event Sourcing, check out our Beginners Guide.
Zero Data Loss
Event Sourcing is capable of generating future value to the business.
Business decisions are generally better when they’re based on data and, because of that, we value data as one of the most important assets a company has - even if you don’t yet know how you could turn this data into business value.
You may not know of a current use for certain data but that doesn’t mean this data won’t be valuable later on. Event Sourcing can be of great worth to businesses due to its zero data loss nature.
With traditional CRUD systems, every time there is a write operation to update or delete a record there is a loss of data unless the previous state before the mutation can be restored. If a system’s state cannot be rebuilt out of its logs, there wouldn’t be any guarantee on what really happened.
Event Sourcing along with an event-native database allows you to capture far more, thereby delivering greater value to your business.
That’s because events in Event Sourcing capture the context of the change. In addition, as each event is immutably stored in an append-only log (your event store) you have a complete history of what led to that change.
The benefits of this is a much richer dataset that you can use in downstream systems to provide much deeper insights to drive business decisions and customer value.
This is especially important in today’s data-driven world where big data analytics and machine learning are vital to increase your competitive advantage. The insight can reveal patterns, trends, and anomalies that would be hard to detect in traditional systems.
Learn how Vispera uses Event Sourcing with EventStoreDB to build a machine learning pipeline.
Improved Analytics Capabilities
Because Event Sourcing allows you to capture raw events that are based on business facts and are highly contextual, you have a wealth of data to feed into downstream use cases.
This is due to the ability to replay events from any point in time. Using an event-native database that sequentially appends those events to an immutable log you can travel backwards and forwards in time. This gives you greater flexibility in providing reports and insights to the business because you aren’t overwriting or deleting data.
You can use temporal querying to deliver a variety of reports based on the goals of each team within the business. You can see some of examples of this in the table below:
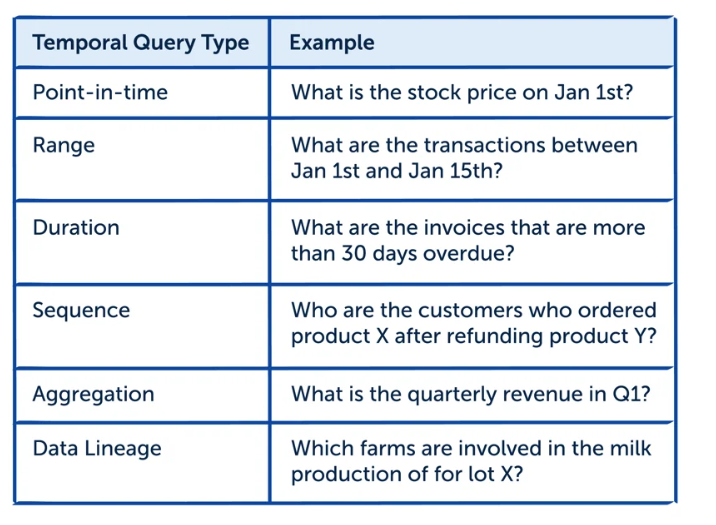
In addition, event-sourced systems allow for the flow of events through streams, which provide similar publish/subscribe functionality as queues, allowing for unprecedented observability, and enabling real-time data.
One example of this is NHS Wales who wanted to build a next-generation NHS app using Event Sourcing and EventStoreDB. The aim of the app was to revolutionize patient care and access to healthcare services.
NHS Wales wanted the app to provide real-time data updates, seamlessly integrate with existing healthcare systems, and give patients access to their data along with ownership of their personal information.
By using Event Sourcing with EventStoreDB, NHS Wales is able to harness the power of real-time data streams to empower patients, improve communication, and ensure seamless integrations with other existing healthcare systems. You can learn more in this article by Computer Weekly.
Reporting
The reporting potential of event-sourced systems is, in fact, one of the most appreciated things about Event Sourcing that makes management excited.
Let’s see it with a realistic example.
Imagine you are a software engineer working for an online clothing store and the marketing team come to you wanting to track user behaviour in the basket. They feel that a customer that decides to remove some item from the basket just before checking out maybe doing so due to having second thoughts, but it’s still a potential customer for these articles.
The idea has a lot of potential so the decision is made to start tracking user behavior within the basket and record details for every item that is removed from a shopping basket less than a minute before checking out.
However, once the new basket is live, the marketing team have to wait for the report to populate with data because there hasn’t been any checkout since the new release went live.
If this scenario had occurred in an event-sourced system you could create this report as a new read model, replay all the events from the beginning of time to create the new projection and, by the time the replay is finished, view all the data in the report without waiting for new purchases, as if the report had always been there from day one.

Increased Competitive Advantage
Event Sourcing can open up the door to greater innovation which increases a business’s competitive advantage. It enables teams to develop innovative solutions through digital transformation and a data-led approach.
One example of this is the cloud credit payment solution developed by Holcim that disrupted the cement distribution sector in multiple countries.
They transformed a very manual payment process that didn’t deliver on customer value or operational efficiencies into a fully automated credit payment solution at point of collection. This not only increased customer satisfaction but led to reduced operational costs for both Holcim and their customers.
Another example is from the sports betting industry where Event Sourcing was used to provide customers with the data quality they required, along with business agility and deep analytics - achieving a clear competitive advantage.
Improved Agility, Scalability and Resilience
Event Sourcing enables developers to break down their monolithic systems that can slow business agility, scalability and innovation.
Combined with an event-native database, Event Sourcing allows for the decoupling of the business’s core logic from other external systems and for the creation of microservices. This enables the modernisation of legacy systems that no longer offer the agility, scalability or resilience the business needs.
With microservices, each part of an application is a collection of smaller services that are independently deployable. This makes it easier to maintain, test and scale around business goals. It also helps to increase software longevity, and allows a development team to do smaller, more frequent deployments making it more flexible.
Learn more about microservices in practice by reading our Kallidus case study.
In addition, decoupling external systems from the core logic creates a more resilient architecture. When your core logic is tightly coupled with a vast array of external systems, any changes to that core logic can also impact those other systems.
Traditional/legacy applications rely on synchronous messaging where the operation is completed before the next step takes place. This can create strong dependencies between external systems.
These synchronous calls can slow down your system that take time to complete, and if they fail can lead to unexpected outage and downtime, bringing the whole system down.
However, with Event Sourcing you can implement asynchronous messaging which doesn’t wait for other processes to be complete before it’s completed. The message is fired off one way and doesn’t rely on a response back.
In the event of service downtime, dependent services can "catch up" when the source becomes available again when each service is back online, enhancing overall system resilience.
One feature that contributes to the fault tolerance of event-sourced systems are event streams. These are essentially logs with strong backup and recovery characteristics. In the event of a failure, downstream projections can be rebuilt by writing the core "source of record" data to the event stream.
Learn how Insureon increased business agility with Event Sourcing
Carry Out Testing & Root Cause Analysis
Connecting business events to their originating events allows for thorough root cause analysis. This traceability ensures visibility into entire workflows, enabling you to pinpoint the exact source of issues and streamline the troubleshooting process. It'll be sure to save you and your team time.
Imagine your domain has complicated or dynamically toggleable business rules and you want to be able to replay the exact steps that happened during a production issue. This is where Event Sourcing shines. You just replay the events one by one and see how that affects the state of the domain every step of the way.
In addition to root cause analysis, automated testing is a must nowadays. It provides security to developers when refactoring, maintaining, or adding more functionality in the code, it contributes to making a more reliable software overall, and it serves as reliable and up to date documentation about the current system’s features.
In order to test functionalities, we go through a given-when-then approach where we prepare the scenario, execute the functionality and make assertions on the result to ensure it does what it’s meant to, and it doesn’t do what it’s not supposed to.
 When using Event Sourcing, these scenarios become easier to prepare and more readable because the system’s preconditions can be built out of a set of events in a self-descriptive way.
When using Event Sourcing, these scenarios become easier to prepare and more readable because the system’s preconditions can be built out of a set of events in a self-descriptive way.
Improved Auditing & Compliance
One of the standout features of Event Sourcing is its ability to provide an immutable audit trail.
Since the source of truth behind the domain in Event Sourcing are the events, they form a natural and unambiguous log of what happened exactly in time.
By storing data as a chronological sequence of events in an event store, you can create a robust and transparent log of all system activities. This not only enhances accountability but also offers a strong foundation for compliance and auditing requirements.
Let's look at how Event Sourcing gives you a good audit trail.
With Event Sourcing we are able to know how the system achieved a certain state in addition to what state that is.
The events are stored in an event store or event log in an ordered manner as they happened and logically grouped by streams associated to what generated them. In order to better explore and correlate these events, they could be read again to extract its information and project it in whichever shape fits the needs.
 Most traditional systems end up including some kind of tracing feature to help developers troubleshoot issues when they arise.
Most traditional systems end up including some kind of tracing feature to help developers troubleshoot issues when they arise.
It’s crucial to know what the system was doing exactly before the problem was revealed in order to reproduce the same scenario and find a solution. This is something that Event Sourcing gives you as every change is recorded, becoming the only source of truth.
Imagine a traditional system with an undesirable situation where an application crashes, but you're unable to reproduce what happened just before because a developer forgot to add some traces.
Now imagine an even trickier scenario where a traditional system has traces everywhere, giving a false sense of security, but for whatever reason, these logs have incorrect data that doesn’t match what happened.
Would we trust the logs? Would we trust the current state? What if somebody edited the state without going through the software’s business logic validation?
Those situations are not so uncommon and are painful to deal with, so having your source of truth as an out of the box trustworthy event log composed of immutable and append-only facts that cannot be changed once they have happened give you an immutable audit trail.
Summary
Event Sourcing used in combination with an event-native database offers a wealth of benefits to a business. From real-time analytics and machine learning, to auditing and compliance. It also offers benefits to software teams by decoupling systems, making it easier to deploy new updates and identify the root cause of any issues that occur. Providing a more robust, agile and scalable system, enabling for faster innovation and driving competitive advantage.