
Our Event Store community matters. So when you make suggestions about EventStoreDB, we do our very best to listen and make changes. One recent change to EventStoreDB is to scavenging, so we wanted to update you on what’s changed, and why it’s better.
Scavenging is an important part of your archival strategy. EventStoreDB is an append-only log and users often reach a state where they only need the latest streams and events written to the database. Once old events are archived, you can mark them for deletion in your live cluster and scavenge them away. This benefits you in terms of free space in your production environment and speed to access events, as your index is also trimmed down.
However, prior to version 22.10, scavenging has been known to be particularly resource intensive and hard to predict. That’s why we took on your feedback and made it our priority to resolve the pain points of the previous scavenging. This resulted in a new way to perform scavenging internally which allows it to be:
- Deterministic
- Resource efficient
- Faster
- GDPR friendlier
How much faster and efficient is the new scavenging?
We did a sample comparison for this article. We wrote 50 million events and 25000 streams in 55 chunks. We ran scavenging on two different versions of EventStoreDB; 21.10.9 and 22.10.1 to be specific. The instance used was a t3.large on AWS with a 1 TB gp3 volume.
Scavenging on version 21.10.9 ran for around 40 minutes, while scavenging on 22.10.1 took only 26 minutes to complete, including the accumulation phase (which we will discuss later takes more time when run the first time). But that is not the only outcome; as you can see in the graph below, the memory usage is also 3 times lower with the new scavenging.
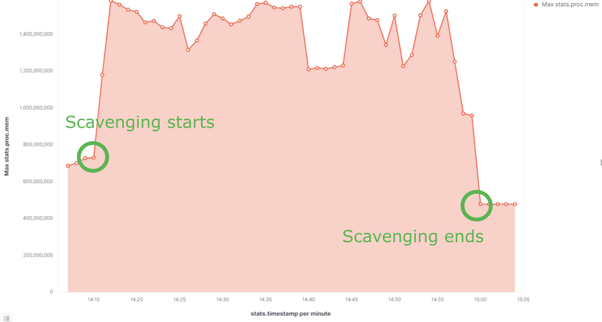
Scavenging on V21.10.9
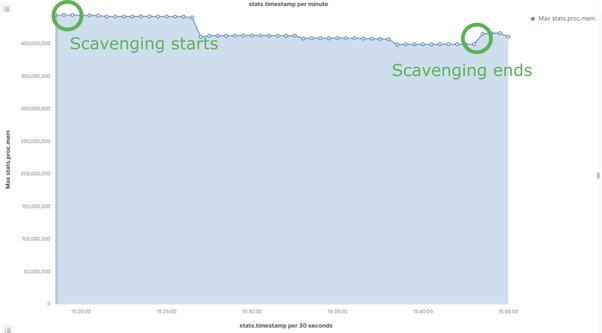
Scavenging on v22.10.1
Our internal tests have shown cases where the new scavenging performs up to 40 times faster than the previous scavenging on subsequent scavenges, depending on the use case.
What makes the new scavenging so much better?
Scavenging now happens in different phases:
- Accumulation - EventStoreDB reads through the log and records any required information for making decisions (such as max age, max count etc). A chunk only needs to be accumulated once. Subsequent scavenges only need to accumulate chunks that have been added since the previous scavenge.
- Calculation - This phase calculates, for each stream, which events can be discarded by the scavenge and what chunks they are located in. Weight is added to the chunks accordingly.
- Execution - This phase uses the calculated data to remove data from the chunks and indexes. Chunks are then merged together as before. Only chunks with sufficient weight to meet the specified threshold are scavenged.
In summary, the first time you run the new scavenge, it creates a 'scavenge point' in the log and completes the current chunk. The log and index are then scavenged up to that point. Scavenge accumulates data that it references throughout the scavenging process. This data is stored in the 'scavenge' directory inside the index directory. It saves information about the different metadata present in the streams which it uses to make scavenging more efficient.
In the old scavenging EventStoreDB didn’t know which entries could be removed until it went through the whole database and index. This caused it to go through all entries, which also forced it to read streams that were then cached in the stream info cache in turn causing memory usage to spike. This does not need to happen in the new scavenging.
What makes the new scavenging deterministic?
Now we know why scavenging uses fewer memory and is faster. Let’s see how it makes scavenging deterministic. Once you run scavenging on one node, the scavenge point is replicated to other nodes in the cluster. The scavenge point contains the position in the log to scavenge up to, a timestamp to consider as 'now' for maxAge tests, and a threshold (0 by default, configurable below).
Any time you start a new scavenge on a node, it looks to see if there are any existing scavenge points that have not yet been scavenged on this node, and uses one of those if available, otherwise it creates a new one. In this way all the nodes in a cluster can be made to scavenge to the same point.
For example, previously if you had a maxAge on a stream on 3 nodes, it was likely that the resultant chunks after scavenging would be of different sizes or even names depending on how the chunks were merged after scavenging. This is no more the case; if you run the new scavenging once on a node, then run scavenging with syncOnly option on another you can make sure that scavenging will happen up to the latest scavenge point. This is essentially what makes the new scavenging predictable.
As mentioned, because we have a new 'scavenge' directory inside the index directory, we recommend the scavenge directory is included in backups to save time having to rebuild it next time a scavenge is run after a restore. As before, ensure that scavenge is not running while a backup is taken if using file-copy backups.
What makes the new scavenging more GDPR Friendly?
The new scavenging is more GDPR friendly than the previous one for two reasons. The first being that contrary to the old scavenging, now the current active chunk is closed and also scavenged. The second reason is that you do not have to set alwaysKeepScavenged to true anymore. It will always remove data if it has to regardless of whether the resultant chunk size is not smaller after scavenging.
Note that this only applies when the threshold is less than or equal to 0 (default value is 0).
How can you use the new Scavenge?
You will need to be on version 22.10.0 or above to use the new scavenge. You can start scavenging from the Web UI in the admin section. Once started, relevant log messages all contain "SCAVENGING: " and have the scavenge id added to the context.
If you would like to finetune the new scavenging you can do the following using the HTTP API.
HTTP GET /admin/scavenge/current
This returns the id of the currently running scavenge if any (and link for stopping it)
HTTP DELETE /admin/scavenge/current
Stops the current scavenge regardless of id. Waits for the scavenge to stop before sending the http response.
HTTP POST /admin/scavenge
throttlePercent (1-100)
This controls the speed of the scavenge. At 100, the scavenge will run as fast as it can. When less than 100, scavenge will take rests to reduce load on the server. e.g. When set to 50 the scavenge will take twice as long by pausing at regular intervals. This allows it to be run with less impact on the server at busy times if required.
A scavenge can be stopped and started with a different throttlePercent, it will continue from where it was up to.
threshold (integer)
New scavenge determines a weight for each chunk, indicating how much it is in need of scavenging. Threshold can fall into one of three ranges
< 0 : scavenge all chunks, even those with 0 weight. In practice this should not be necessary.
= 0 : scavenge all chunks that have a positive weight. i.e. scavenge all chunks that have anything to scavenge. This is the default.
> 0 : scavenge all chunks whose weight is greater than the threshold.
If you find that scavenge is spending a long time scavenging chunks without removing much information from them, you can provide a threshold greater than zero. The weights of the chunks that are being scavenged or skipped can be found in the log files by searching for "with weight". The weight of a chunk is approximately double the number of records that can be removed from that chunk.
The threshold is captured inside the scavenge point and cannot be changed for that scavenge point. This is so that the scavenge produces the same results on each node.
e.g. POST to http://127.0.0.1:2113/admin/scavenge?throttlePercent=100&threshold=0
syncOnly (boolean)
When set to true, this prevents a new scavenge point from being written, meaning that the scavenge will only run if there is already a scavenge point that it hasn't yet run a scavenge for (perhaps written by another node)
startFromChunk
This setting is now ignored and not used by the new scavenging. It will be deprecated in future releases.
We have new database options to add more control on Scavenging
--Scavenge-Backend-Cache-Size
This is the size, in bytes, of the cache that scavenge will use. Default 64 MiB.
--Scavenge-Hash-Users-Cache-Capacity
The number of stream hashes to remember when checking for collisions. Default 100k. If the accumulation phase is reporting a lot of cache misses above the number of new streams, it may benefit from increasing this number.
--Scavenge-Backend-Page-Size
The page size, in bytes, of the scavenge database. Default 16 KiB
Do you have any questions about the new Scavenge?
Read more about its release or ask your questions in our Discuss forum.